A New Axis of Sparsity for Large Language Models
Introduction: The Memory Problem in AI
Imagine having to solve a complex math problem while simultaneously trying to remember basic facts like "2+2=4" or "Paris is the capital of France." That's essentially what current Large Language Models (LLMs) do every single time they process text. They waste precious computational power "recomputing" simple facts they've seen thousands of times before.
DeepSeek AI and Peking University have just published a groundbreaking paper titled "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models" that introduces Engram – a revolutionary approach that gives AI models a dedicated "memory bank" for instant recall, freeing up their computational power for actual reasoning.
What is Engram? The TL;DR
Think of it like this:
- Before Engram: Your AI is like a student who has to re-derive every formula from scratch during an exam, even for basic equations they've seen a million times.
- With Engram: Your AI is like a student with a well-organized formula sheet – they can instantly reference known facts and spend their mental energy on solving the actual problem.
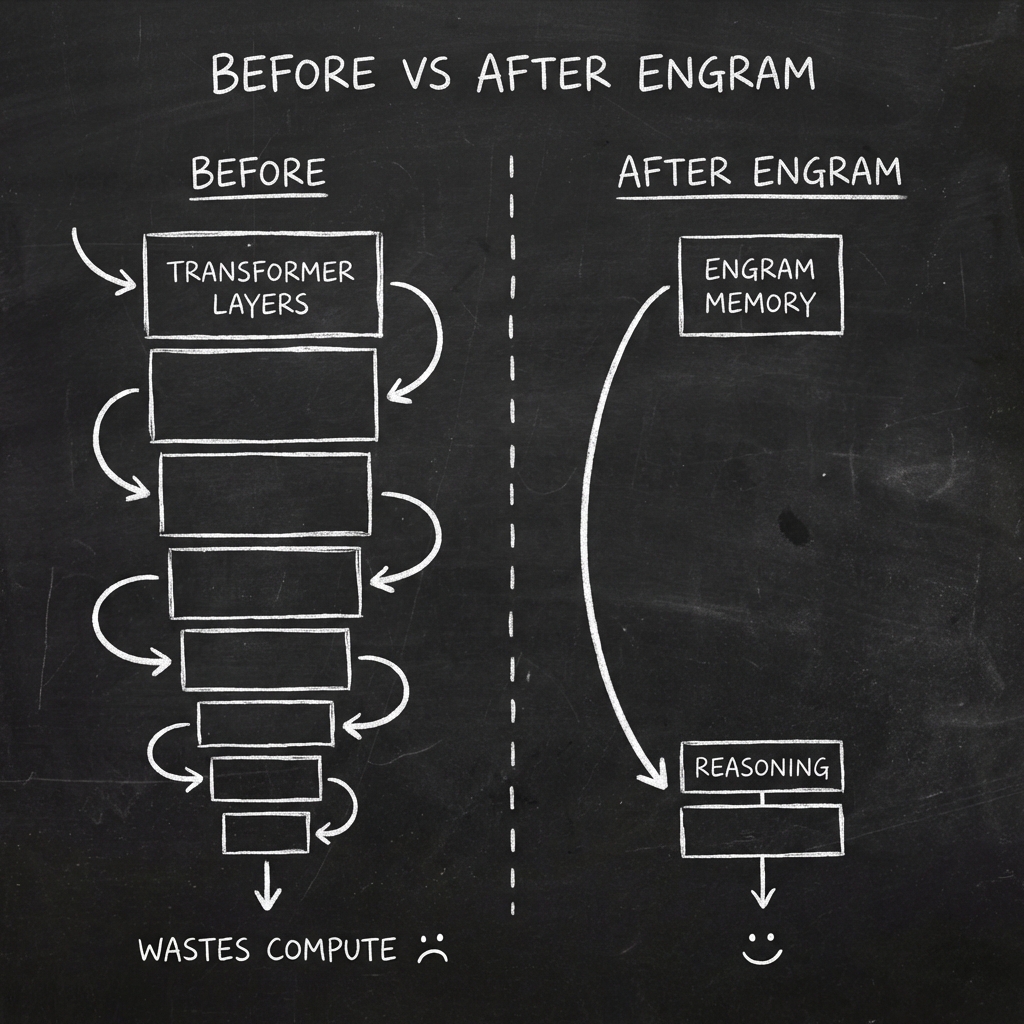
Why Do We Need This?
The Inefficiency of Traditional Transformers
Current LLMs based on the Transformer architecture have a fundamental limitation: they lack a native way to efficiently store and retrieve static knowledge.
When a model encounters common phrases like:
- "The capital of France is..."
- "E = mc²"
- "Once upon a time..."
It has to process these through multiple layers of neural networks, consuming:
- ✗ Valuable GPU compute power (FLOPs)
- ✗ Expensive high-bandwidth memory (HBM)
- ✗ Attention capacity that could be used for understanding context
The Sparsity Revolution
The AI community has been exploring "sparsity" – the idea that you don't need to activate the entire model for every task. The most famous example is Mixture-of-Experts (MoE), which routes different inputs to specialized "expert" sub-networks.
MoE gave us conditional computation (only use the parts of the brain you need).
Engram introduces conditional memory (only store and retrieve what you need, when you need it).
Together, they form a powerful duo: smart computation + smart memory.
How Does Engram Work?
1. The Memory Bank: Modernized N-gram Embeddings
Engram creates a searchable database of word sequences (N-grams) – think of it as a massive lookup table for common patterns.
• Input: "The capital of France"
• Engram lookup: → "is Paris" (retrieved in O(1) constant time)
• No need to "compute" this through 40+ transformer layers!
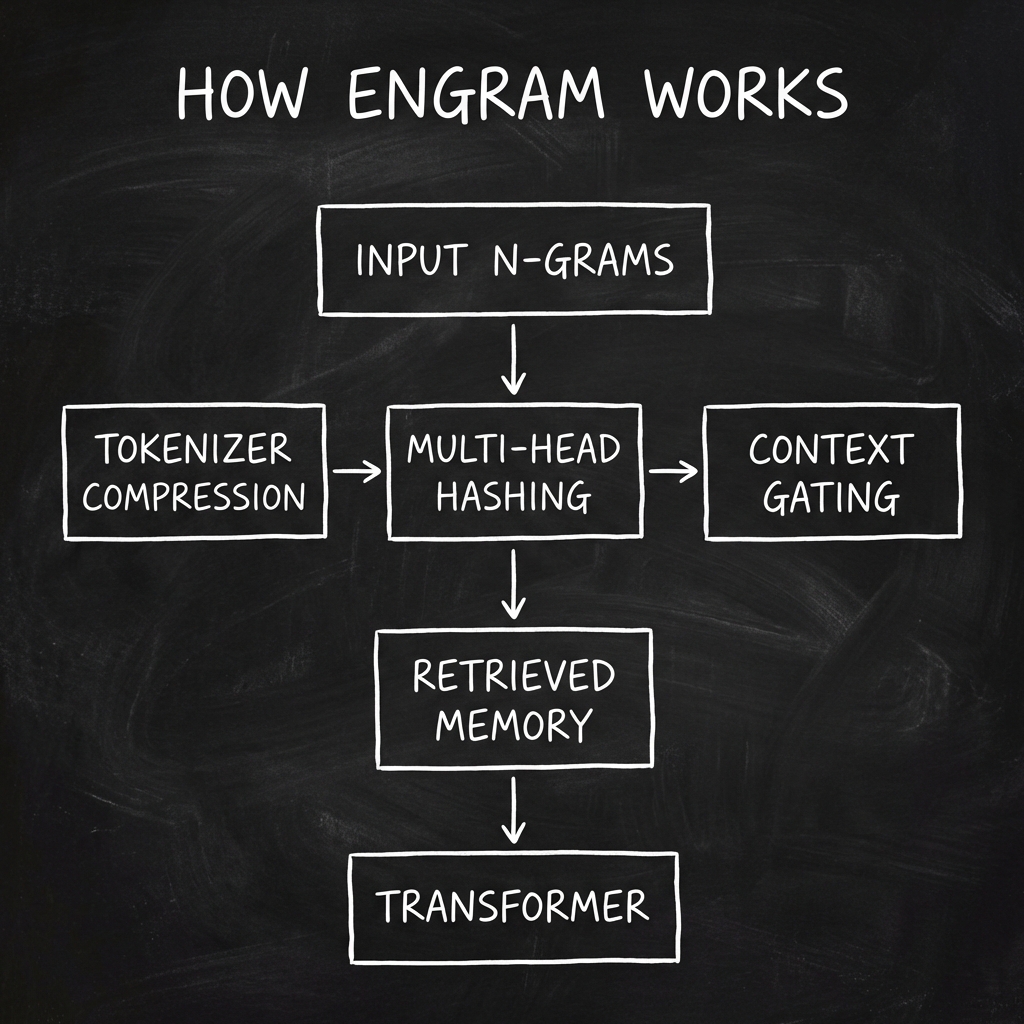
2. Three Key Innovations
A. Tokenizer Compression: Reducing Redundancy
Before storing information, Engram "normalizes" tokens:
- "Apple", "apple", "APPLE" → all treated as the same concept
- This reduces the effective vocabulary by ~23%
- Less storage, faster lookups
B. Multi-Head Hashing: Collision-Free Storage
Storing every possible word combination would require infinite memory. Engram uses multiple hash functions (like having several phone books):
- If one hash gives the wrong result, others provide the correct one
- Minimizes "collisions" where different patterns map to the same location
- Enables massive memory tables stored efficiently in system RAM (DRAM) instead of expensive GPU memory
C. Context-Aware Gating: Smart Retrieval
Not all retrieved memories are relevant. Engram includes a gating mechanism:
- Evaluates: "Does this retrieved pattern fit the current context?"
- If yes → use it
- If no → ignore it
- This prevents noise and ensures only helpful information is used
3. Integration with the Transformer
Engram doesn't replace the Transformer – it augments it:
- Injected early in the model's layers
- Offloads static pattern reconstruction before the model wastes compute
- Retrieved memory is lightly processed and added back into the model's state
- The rest of the network focuses on complex reasoning
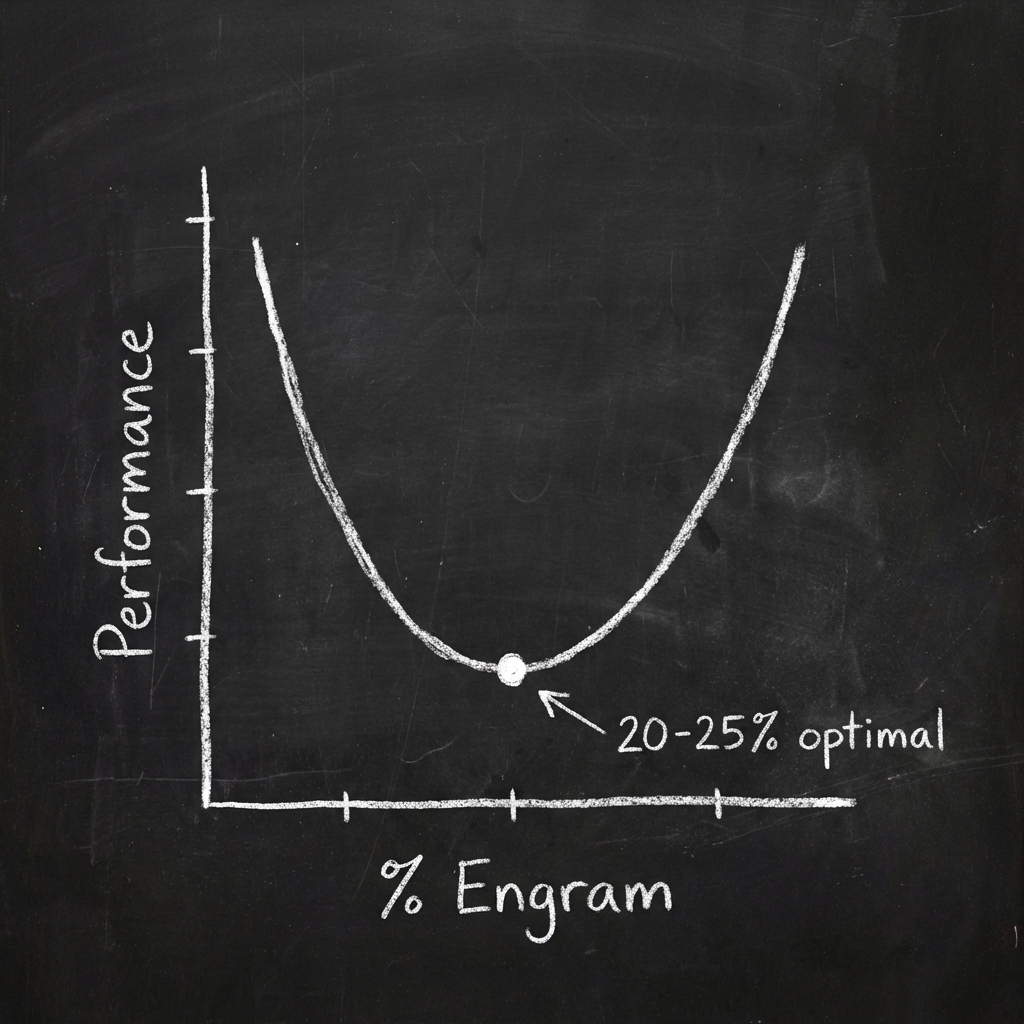
The U-Shaped Scaling Law
The researchers discovered something fascinating: the optimal balance between MoE (computation) and Engram (memory) follows a U-shaped curve.
Allocating 20-25% of sparse parameters to Engram + the rest to MoE = optimal performance
- Too little memory → model wastes compute on static patterns
- Too much memory → not enough compute for reasoning
- Just right → best of both worlds
This is called the Sparsity Allocation Problem, and it's now solved.
Performance: The Numbers Don't Lie
The researchers scaled Engram to 27 billion parameters and compared it against pure MoE models with the same parameter count and computational budget (FLOPs).

| Benchmark | Improvement |
|---|---|
| MMLU (knowledge) | +3.4 points |
| CMMLU (Chinese knowledge) | +4.0 points |
| BBH (reasoning) | +5.0 points |
| ARC-Challenge (reasoning) | +3.7 points |
| HumanEval (coding) | +3.0 points |
| MATH (mathematics) | +2.4 points |
| Multi-Query NIAH (long-context) | 84.2 → 97.0 |
Why Does Engram Boost Reasoning?
The researchers conducted "mechanistic analyses" to understand why Engram improves reasoning:
1. Deepening the Network
- By handling static patterns early, Engram frees up the model's later layers
- These layers can now focus entirely on complex, multi-step reasoning
- Effect: The network becomes "effectively deeper" for reasoning tasks
2. Freeing Attention for Global Context
- Attention mechanisms no longer waste capacity on local, repetitive patterns
- They can focus on understanding global context and long-range dependencies
- Effect: Massive boost in long-context retrieval (84.2 → 97.0 on NIAH benchmark)
Infrastructure Efficiency: The Hidden Superpower
Deterministic Addressing = Runtime Prefetching
- Engram's lookups are deterministic (predictable)
- The system can prefetch data from host memory (DRAM) before it's needed
- This happens in the background with negligible overhead
• You can store massive memory tables in cheap system RAM
• Not limited by expensive GPU memory (HBM)
• Decouples compute power from memory capacity
• Scale memory almost infinitely without buying more GPUs
Real-World Impact: This makes Engram incredibly cost-effective for deployment at scale.
The Future: Conditional Memory as a Modeling Primitive
The researchers envision conditional memory as an indispensable component for next-generation AI models.
Just as:
- Attention mechanisms became standard in 2017 (Transformers)
- Mixture-of-Experts became standard for scaling (GPT-4, Gemini)
Engram-style conditional memory could become the third pillar of modern LLM architecture.
Potential Applications:
- Retrieval-Augmented Generation (RAG): Built-in, no external database needed
- Domain-Specific Models: Pre-load specialized knowledge (medical, legal, scientific)
- Personalized AI: Store user-specific patterns and preferences
- Multimodal Models: Efficient storage of visual patterns, audio signatures, etc.
Code and Reproducibility
The best part? The code is open-source!
🔗 GitHub Repository:
github.com/deepseek-ai/EngramThe research community can now:
- Experiment with Engram
- Integrate it into existing models
- Extend the concept to new domains
Key Takeaways
- What: Engram is a conditional memory module that enables O(1) knowledge lookup in LLMs
- Why: Current Transformers waste compute recomputing static patterns; Engram separates memory from reasoning
- How: Uses modernized N-grams with tokenizer compression, multi-head hashing, and context-aware gating
- Impact: Significant gains in knowledge (+3-4 points), reasoning (+5 points), and long-context handling (84→97)
- Efficiency: Deterministic addressing enables prefetching from cheap DRAM, not expensive GPU memory
- Future: Conditional memory is poised to become a standard primitive in next-gen AI architectures
Conclusion: A New Era of Efficient AI
The Engram paper represents a fundamental shift in how we think about LLM architecture. By introducing conditional memory as a complement to conditional computation, DeepSeek has opened a new dimension for scaling AI models efficiently.
As we move toward increasingly capable AI systems, innovations like Engram will be crucial for making them not just more powerful, but also more efficient, cost-effective, and accessible.
The age of conditional memory has begun.
References
- Paper: "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models"
- arXiv: arxiv.org/abs/2601.07372
- Authors: DeepSeek AI & Peking University
- Published: January 12, 2026
- Code: github.com/deepseek-ai/Engram